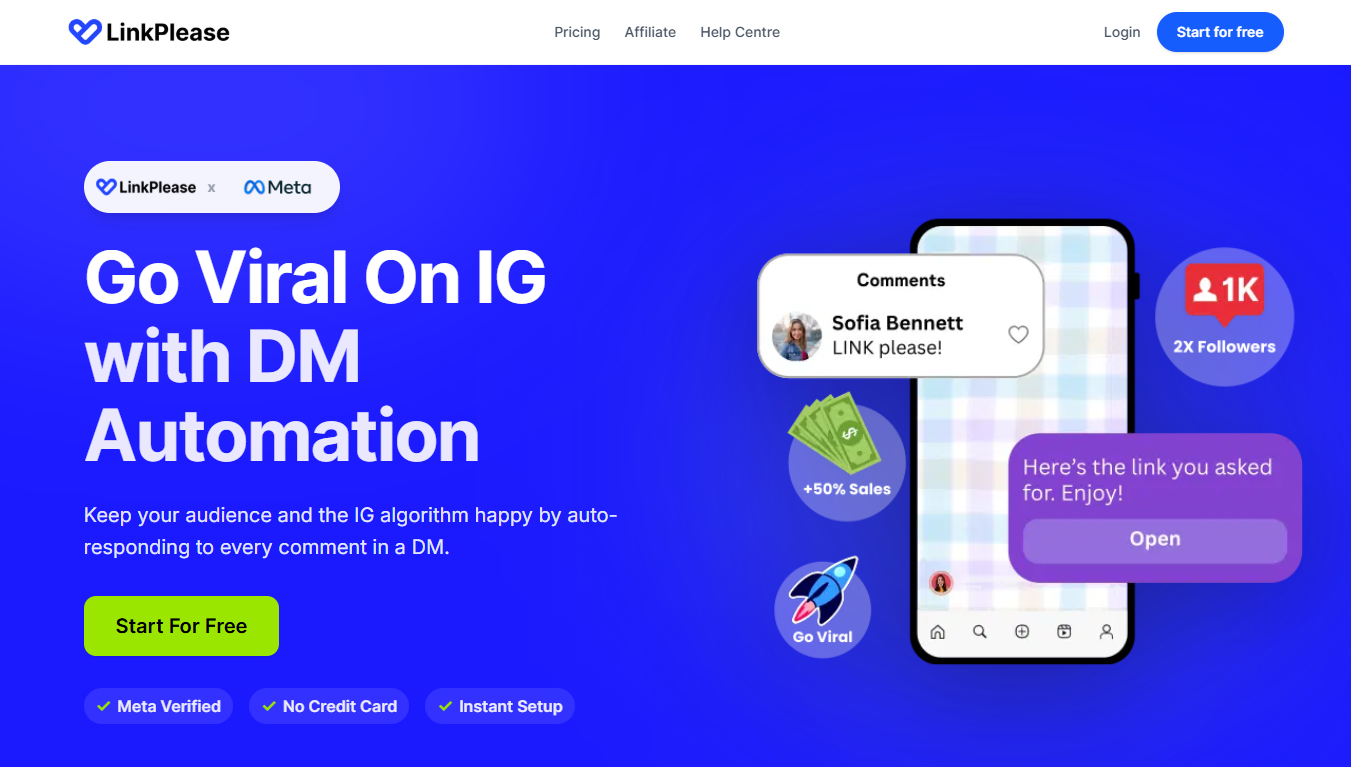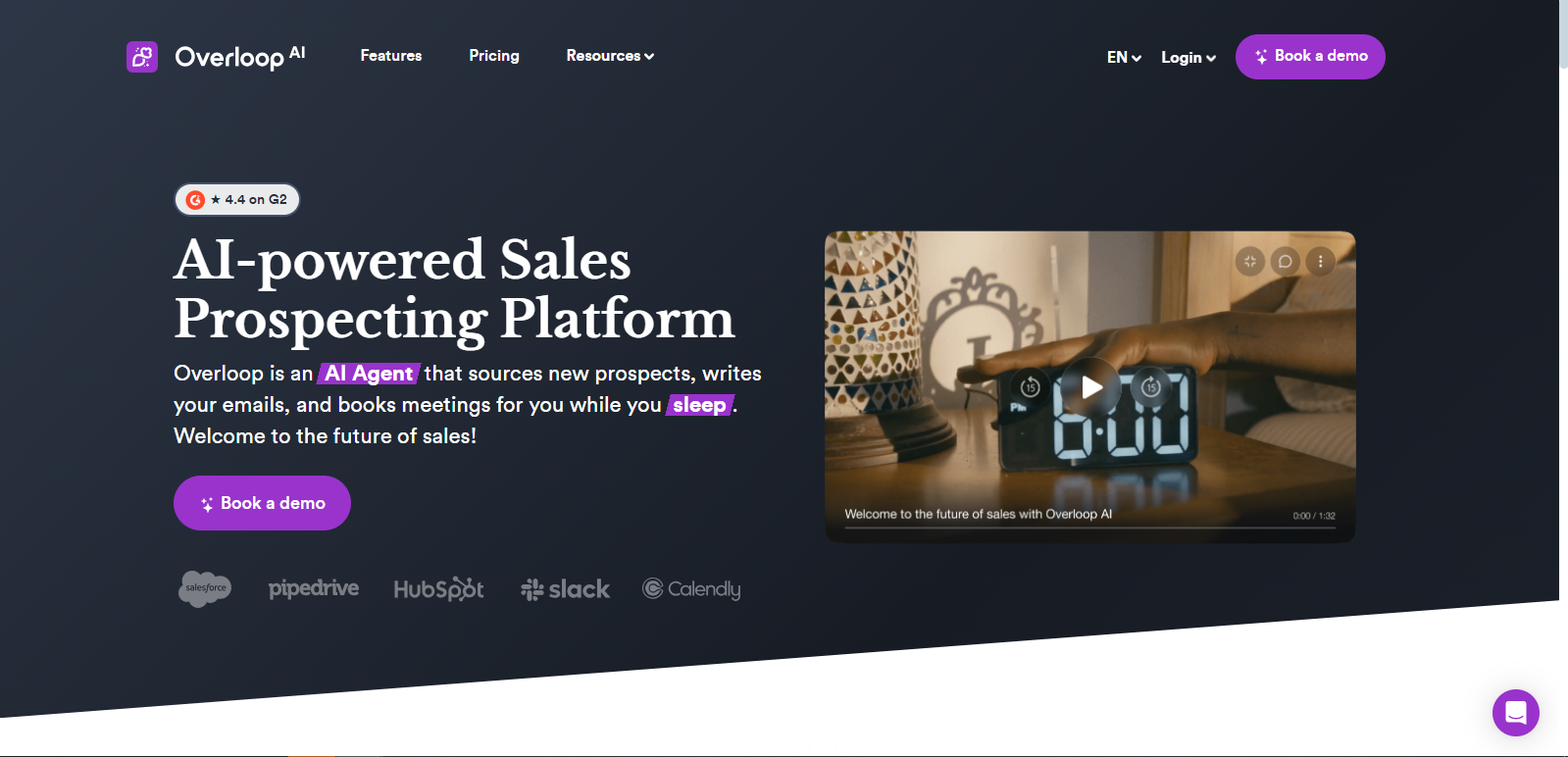
Overall Value Overloop AI gives sales and growth teams an unfair advantage. Designed to simplify lead generation and outbound sales,
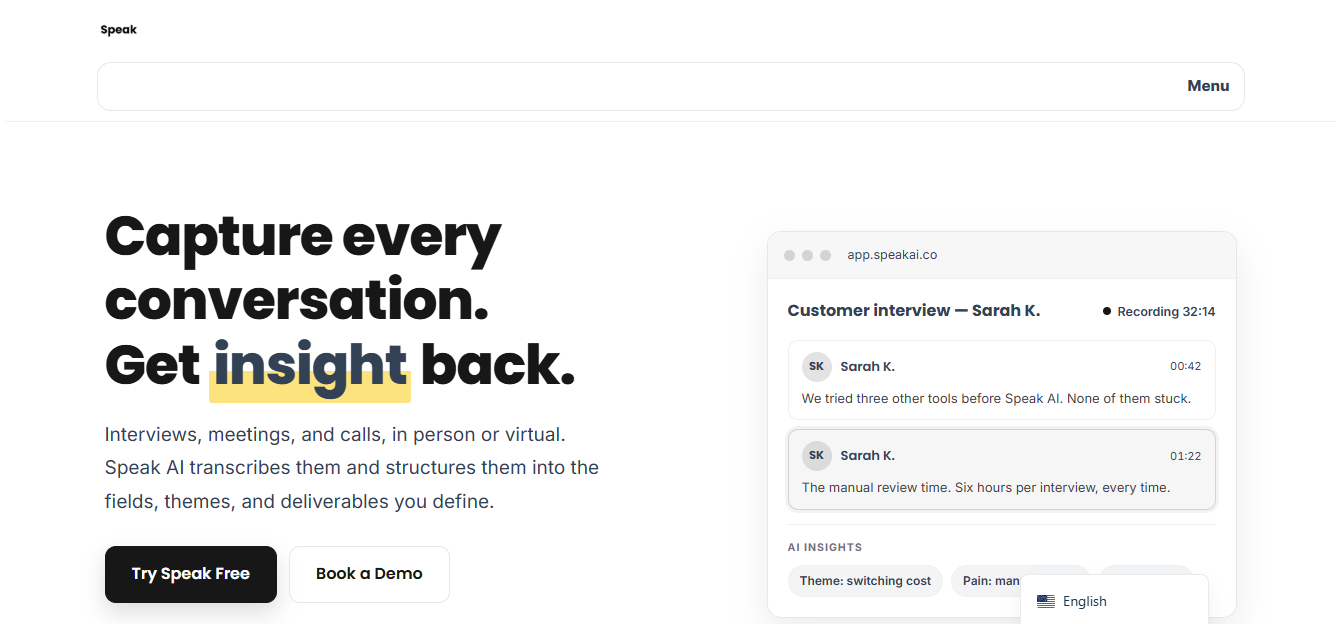
Overall Value: Speak AI is the all-in-one voice Agent platform built for researchers, founders, sales teams, and developers who want
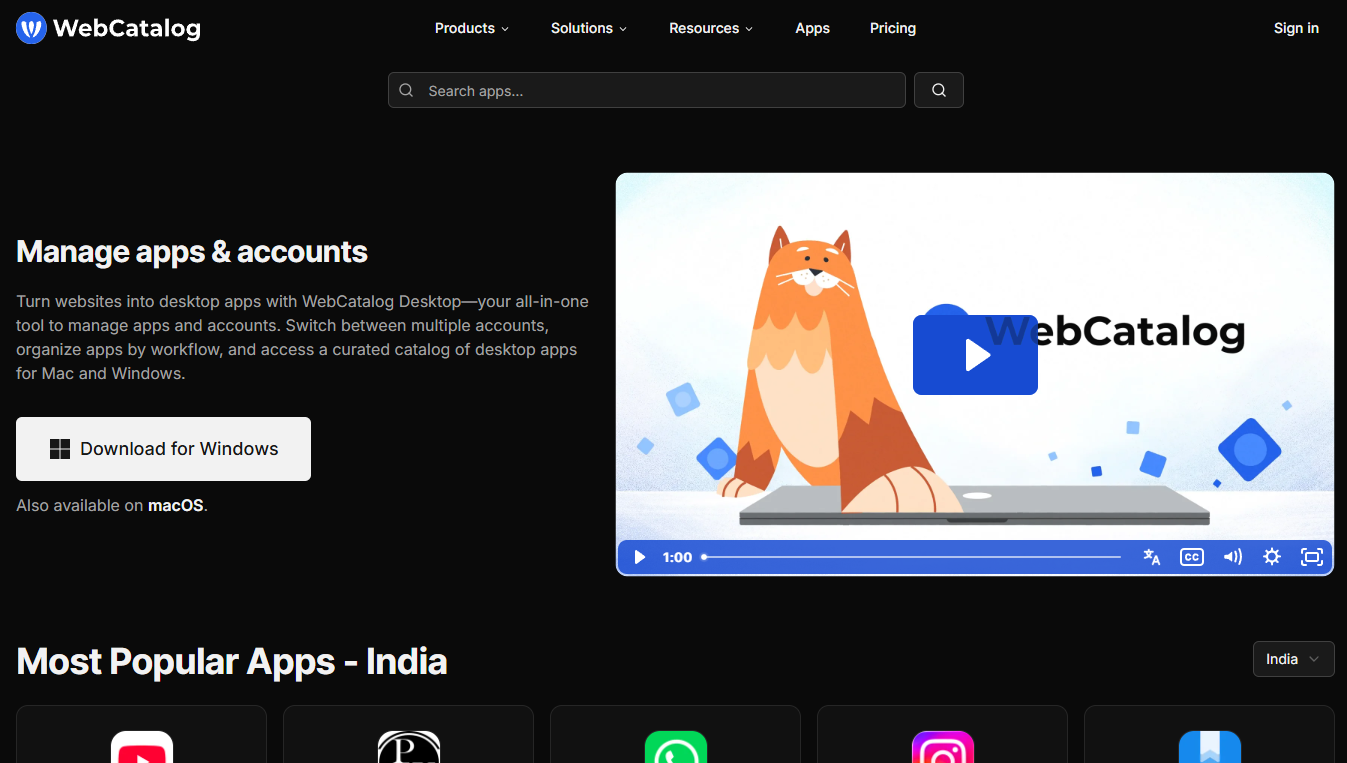
Overall Value: WebCatalog solves the chaos of modern web-based work. If you juggle 20+ browser tabs, multiple logins for Gmail,